Cache Coherency Series: Part 1 — Introduction
Published:
Modern CPUs are extremely fast — so fast, in fact, that executing a single instruction often takes less time than accessing data from main memory (RAM). To avoid the bottleneck of accessing data from RAM, processors utilize caches, which are small and fast memory located near each CPU core. Having the cache can significantly reduce an amount of time to access some data from RAM.
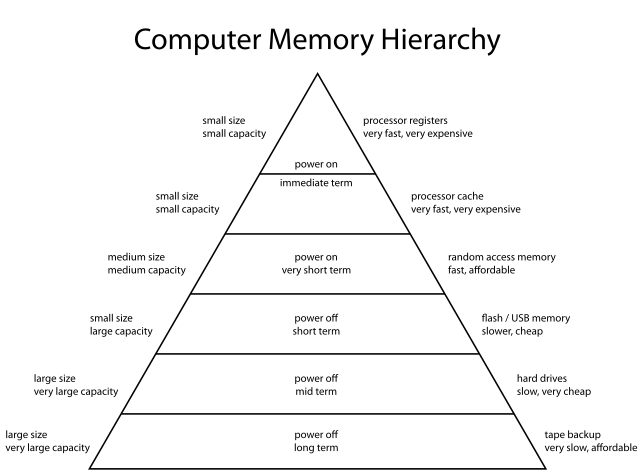
Memory Hierarchy Diagram
In multicore programming, we deal with several CPU cores operating in parallel. Each core can have its own cache. When CPU wants to access a piece of memory, such as a single variable, it does not load just that variable into its cache. Instead, it loads a block of memory called a cache line, which is a block of memory.
For example, if the cache line size is 64 bytes and a core wants to get an integer (typically 4 bytes) from that cache line, the entire 64-byte cache line, containing that integer, will be fetched from RAM to the cache. This behavior improves performance by exploiting spatial locality, which has the idea that nearby data tends to be accessed soon.
The entire cache line is loaded to the core’s cache even if only one element is called.
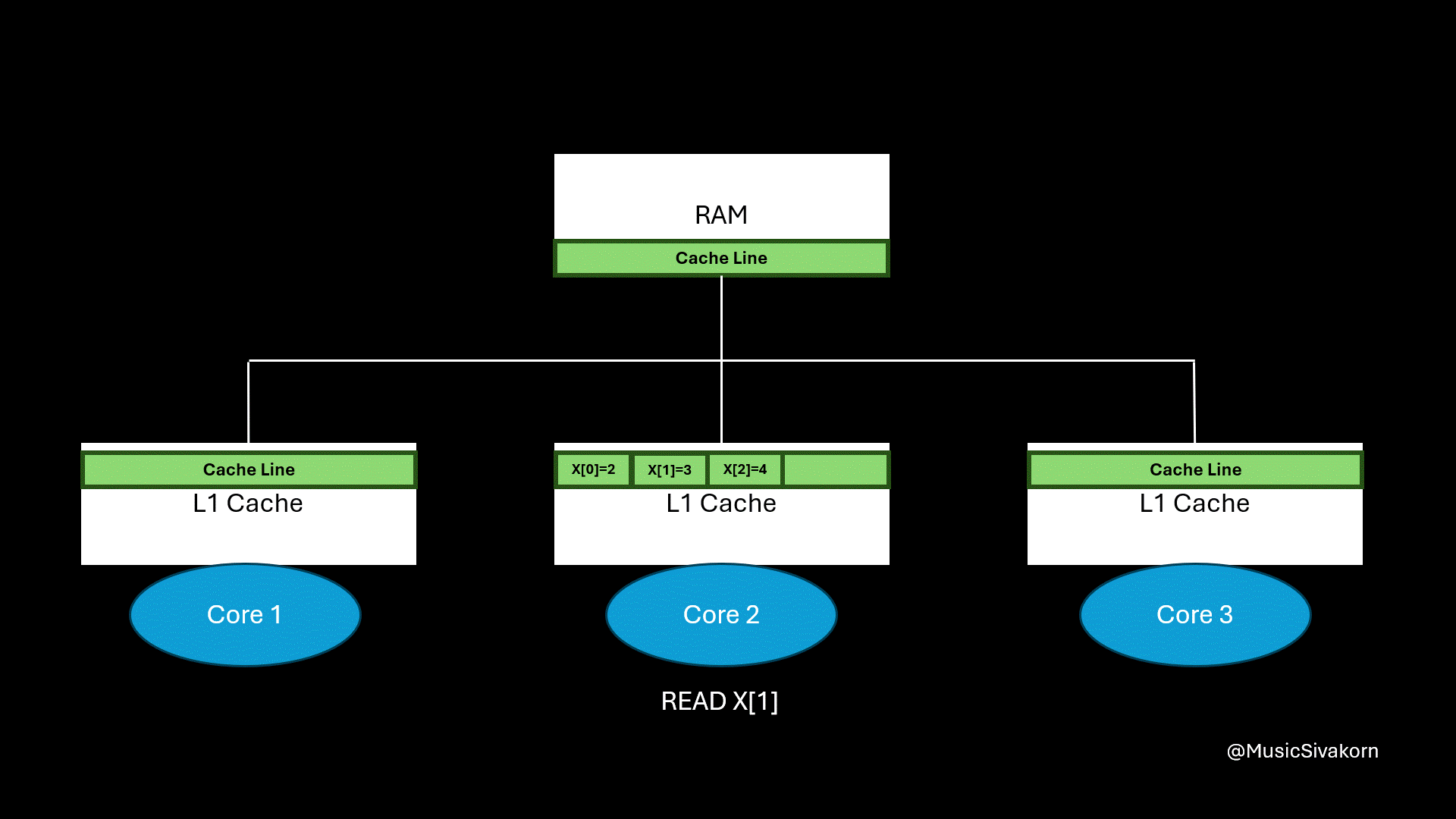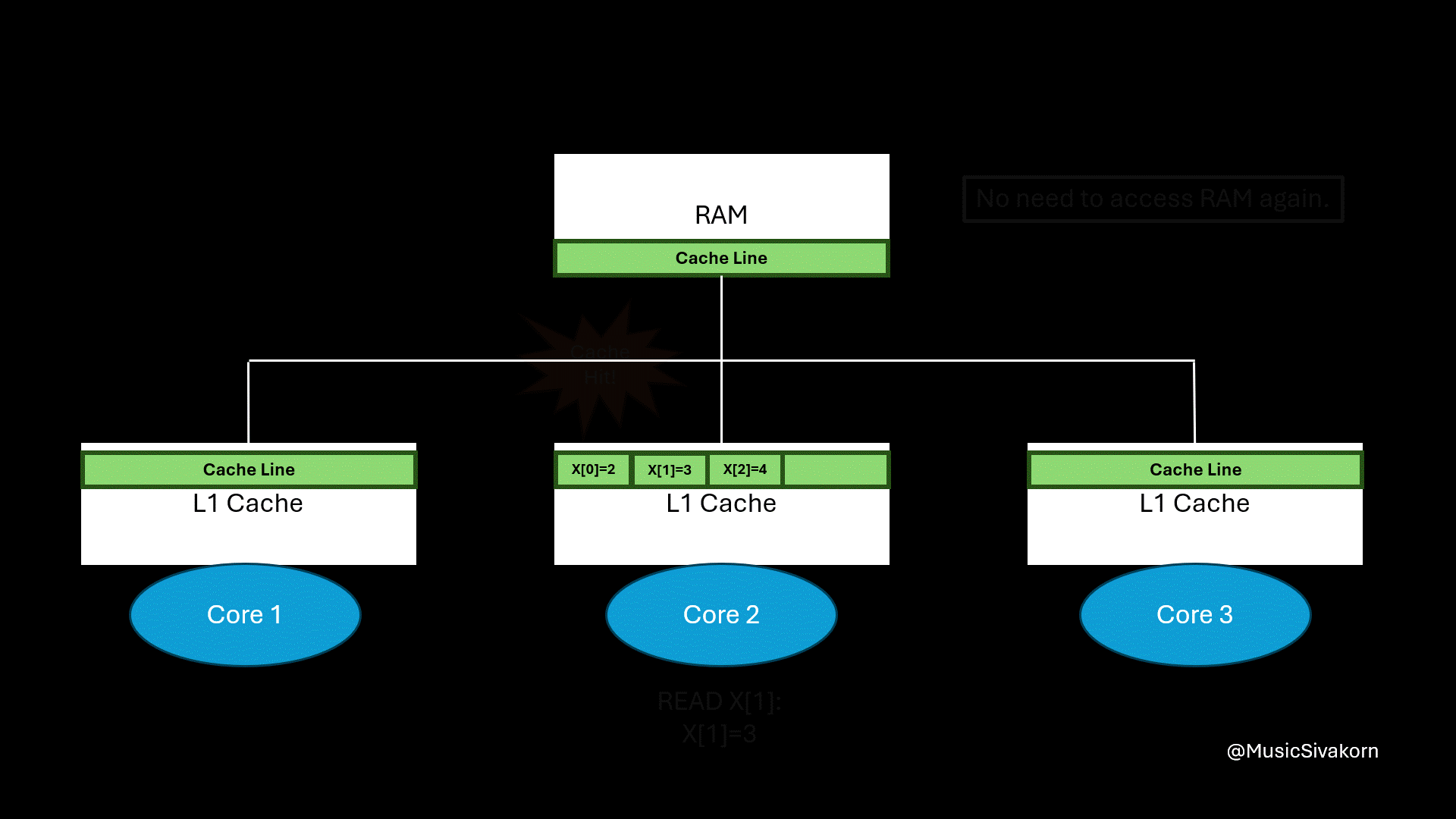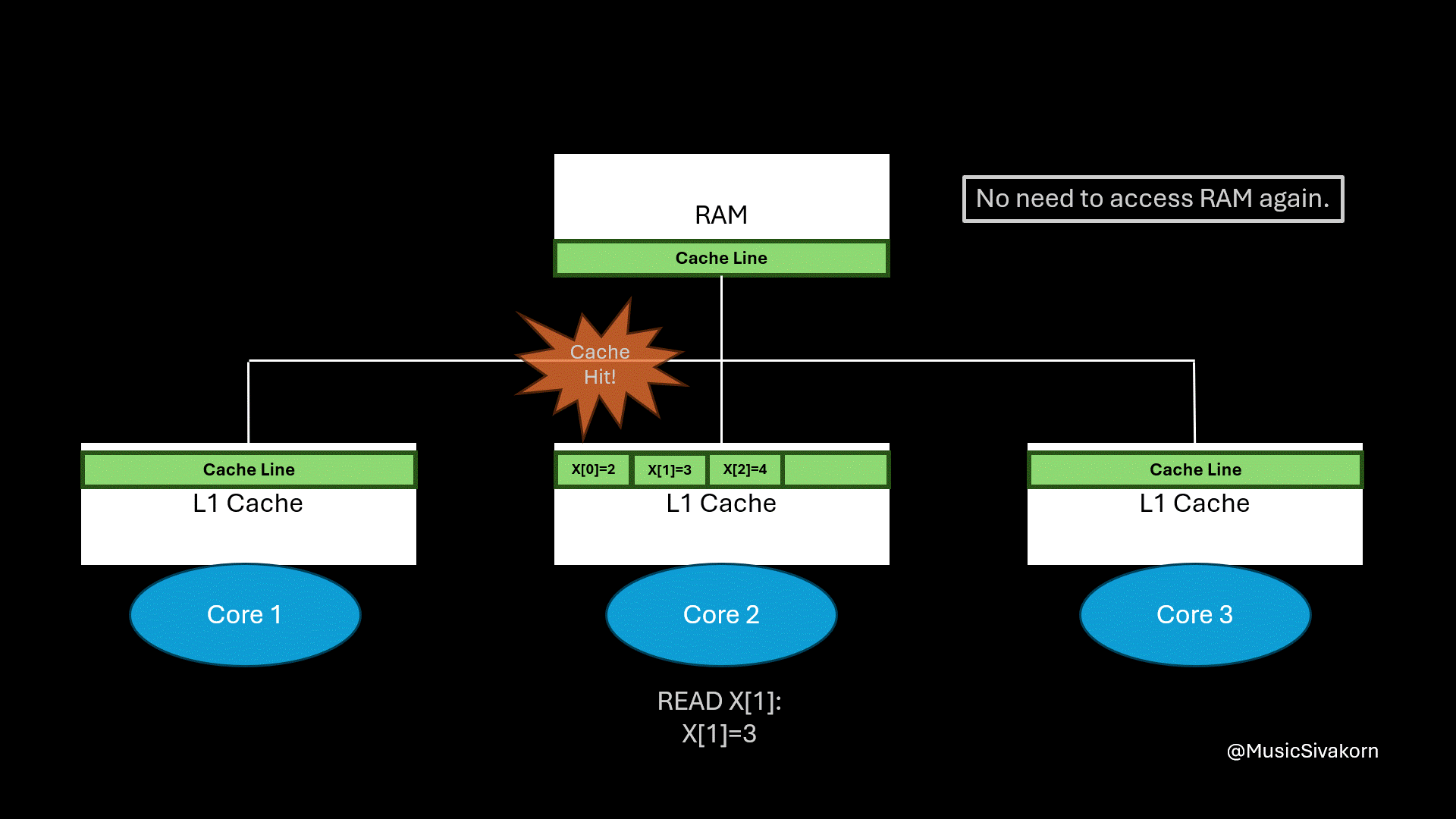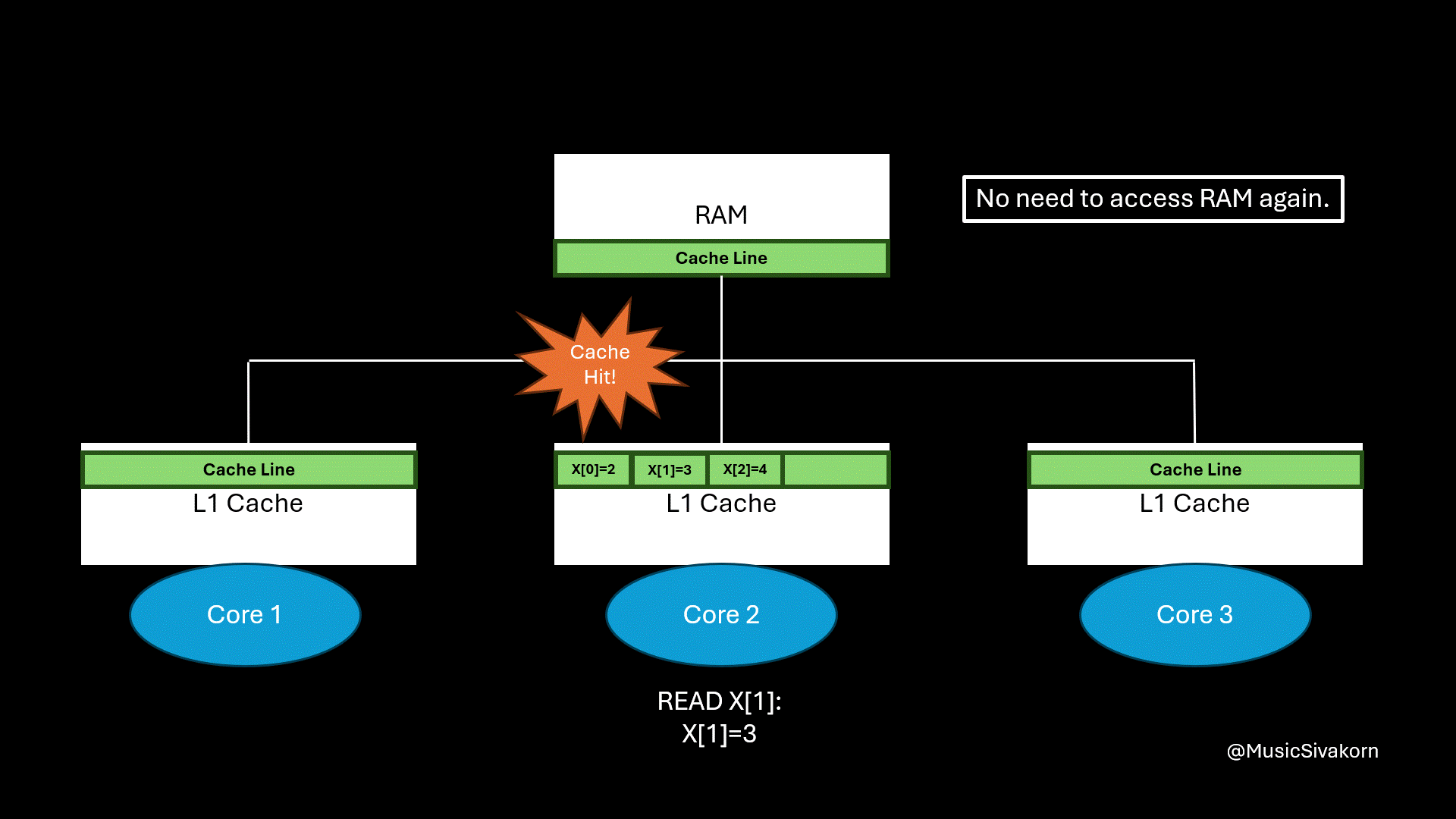
How spatial locality helps.
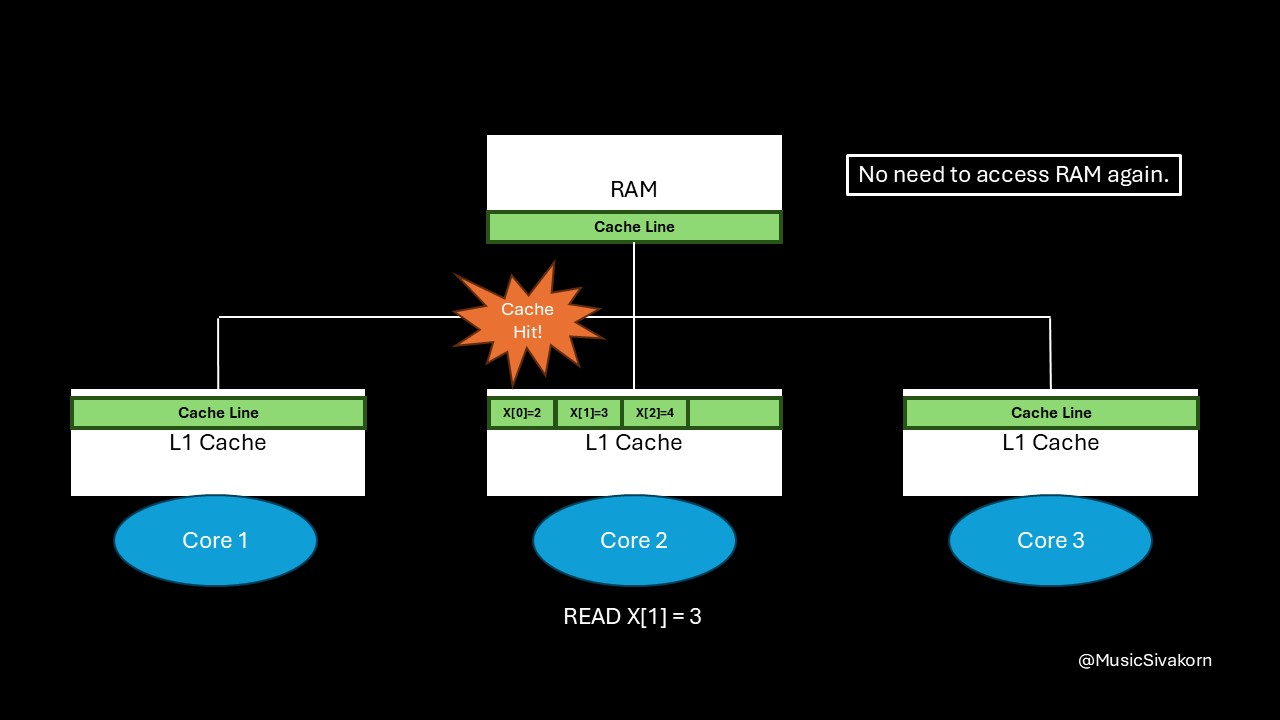
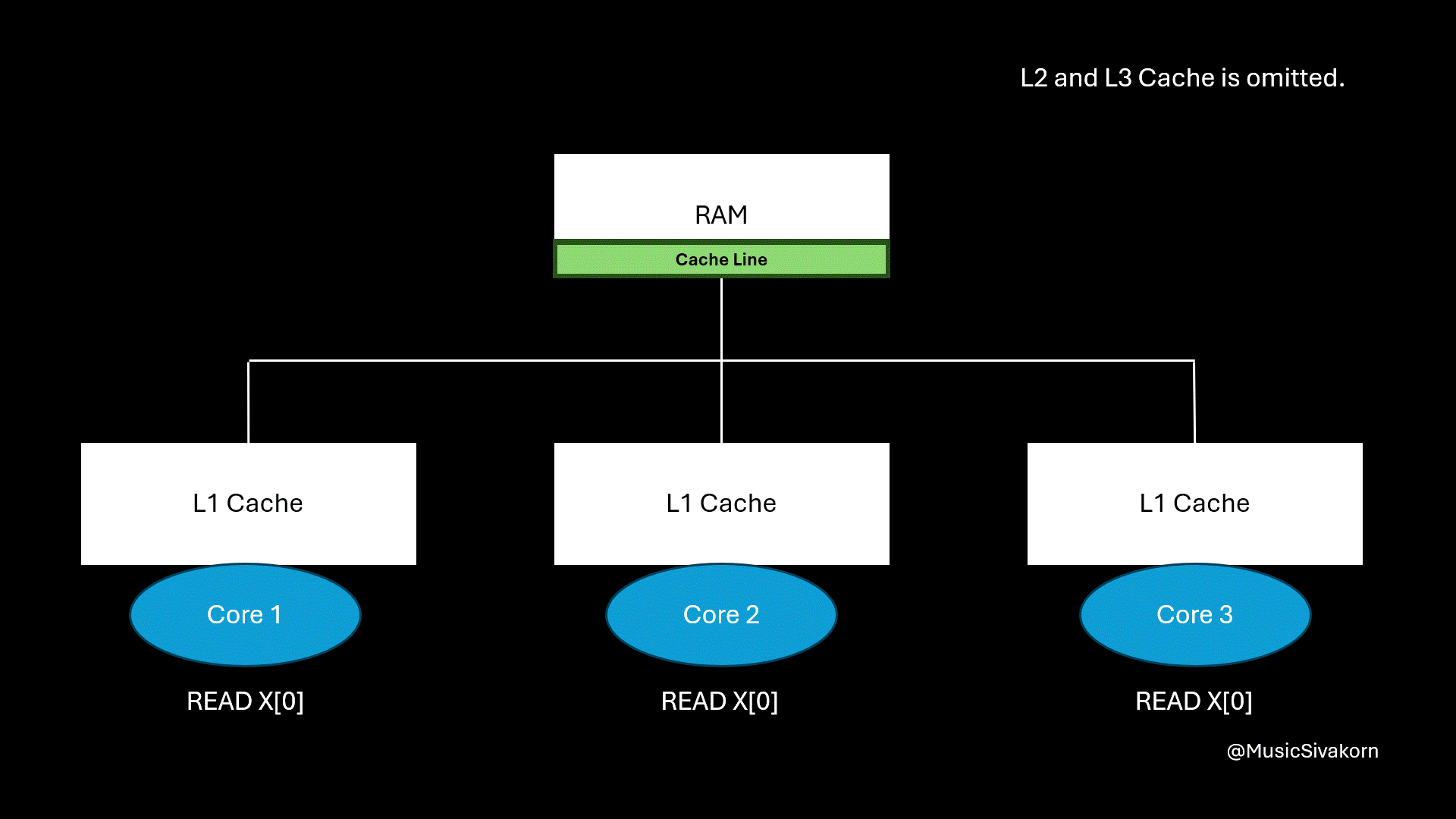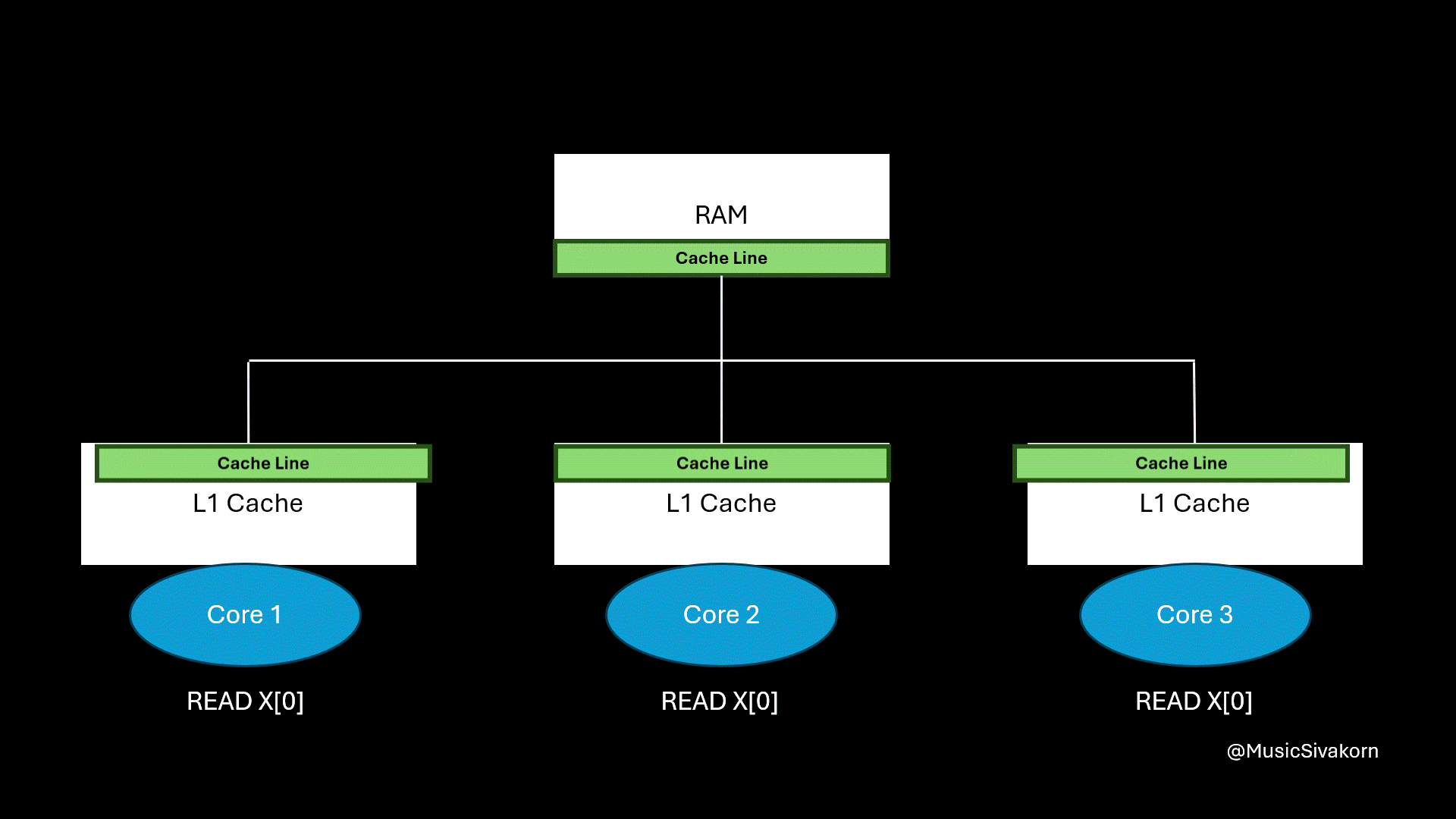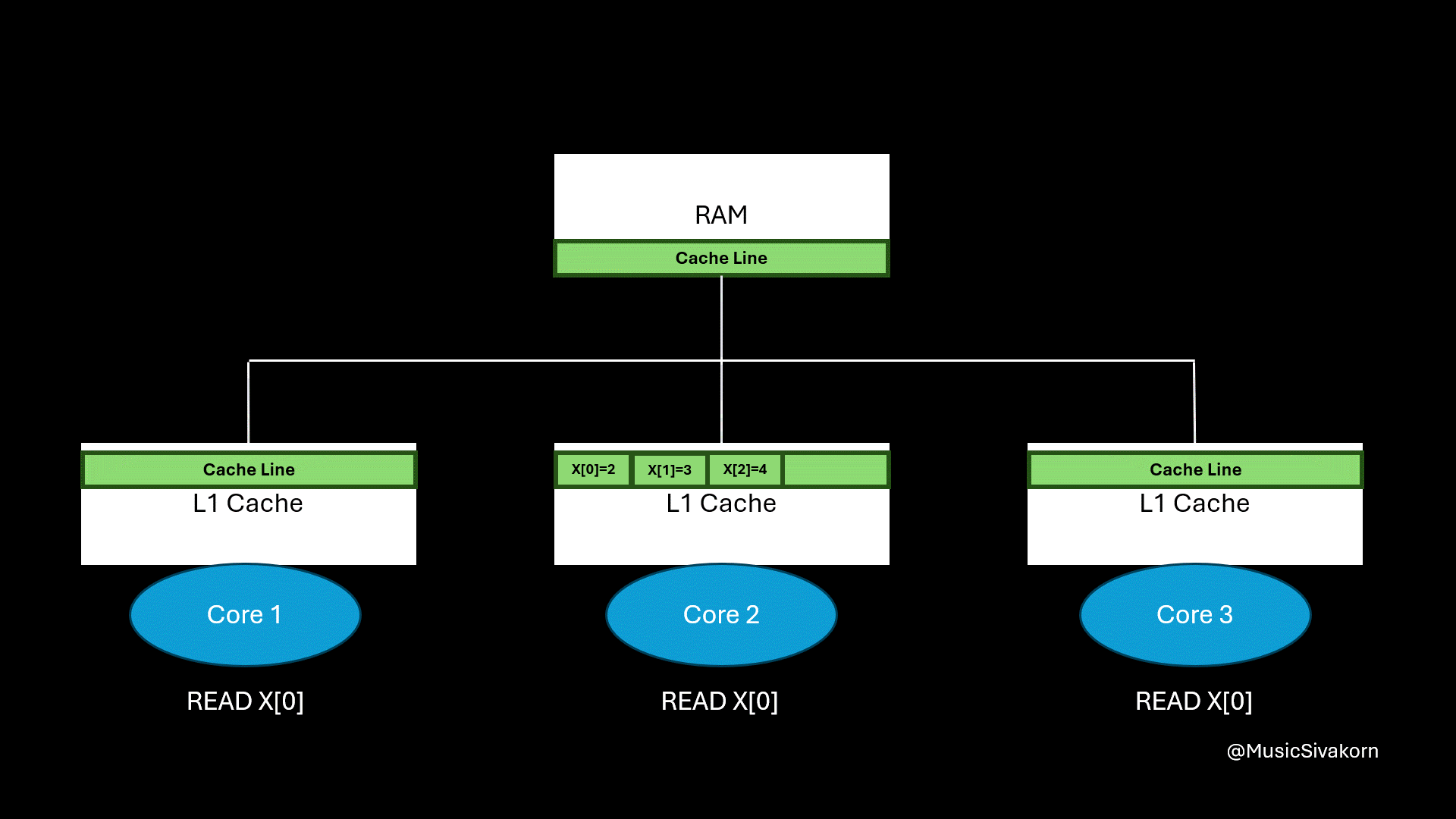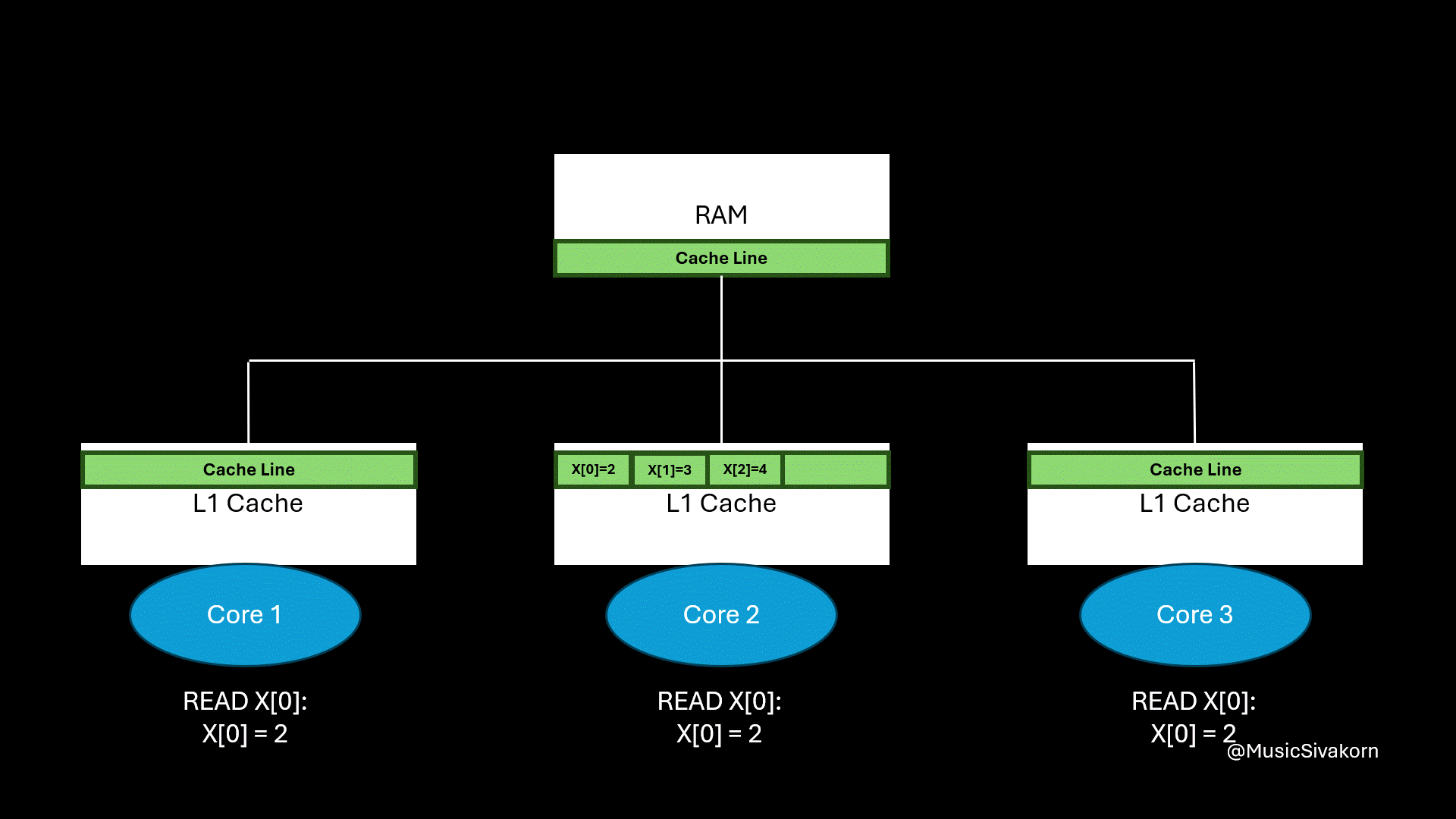
The final result of applying spatial locality.
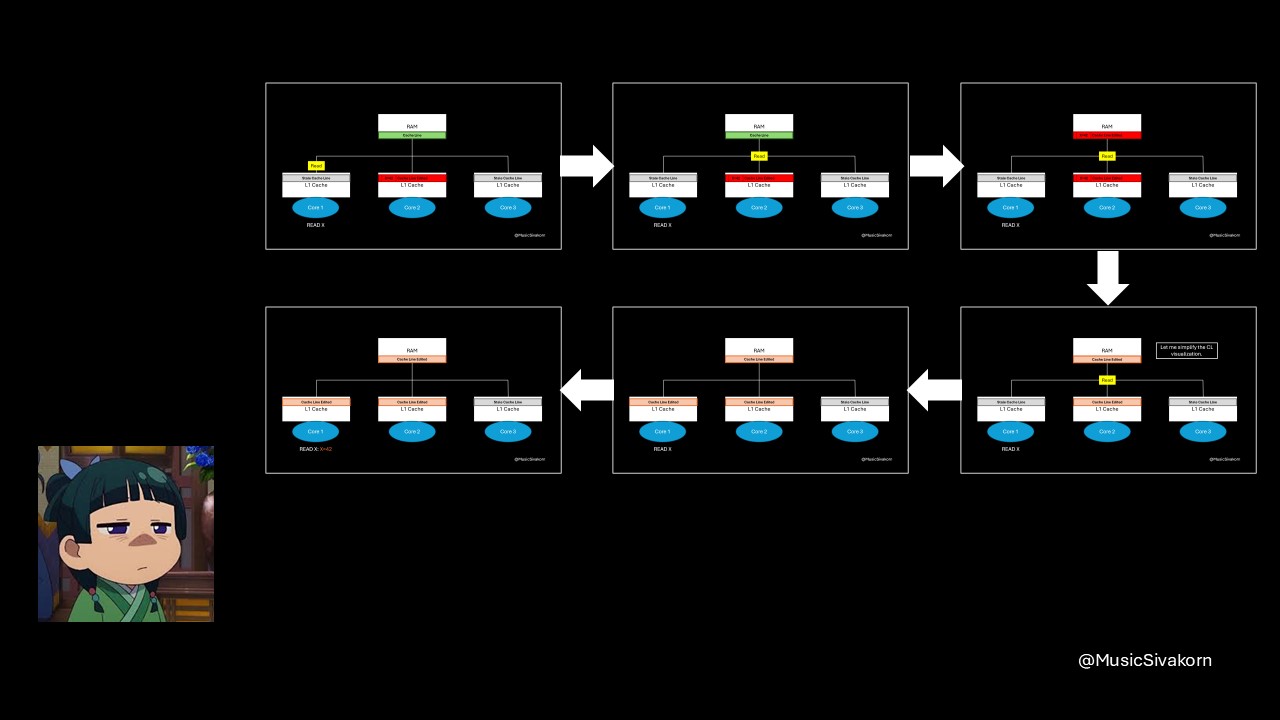
However, this caching method introduces a challenge. What happens when multiple cores try to access or modify the same piece of data, such as a variable?
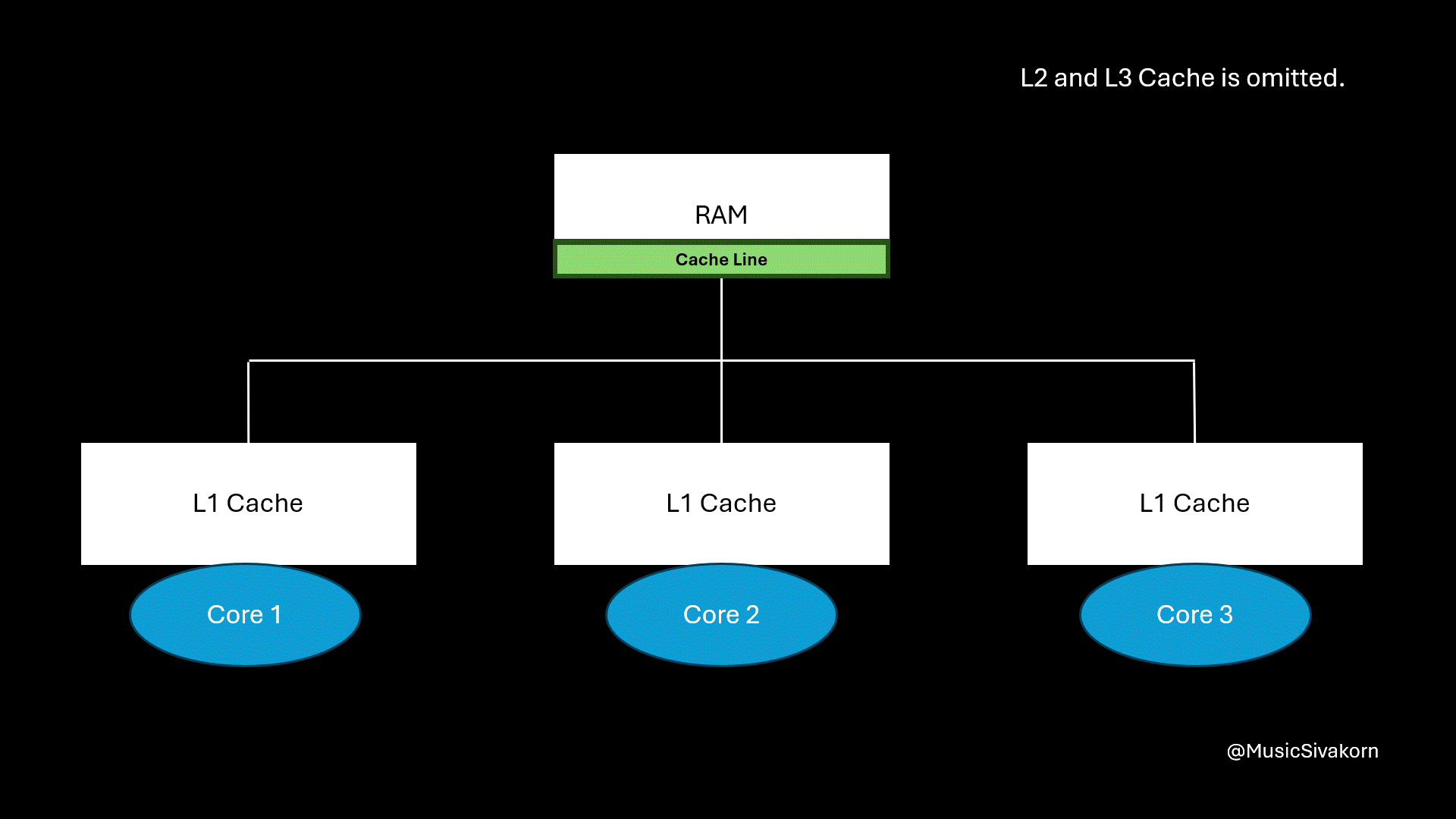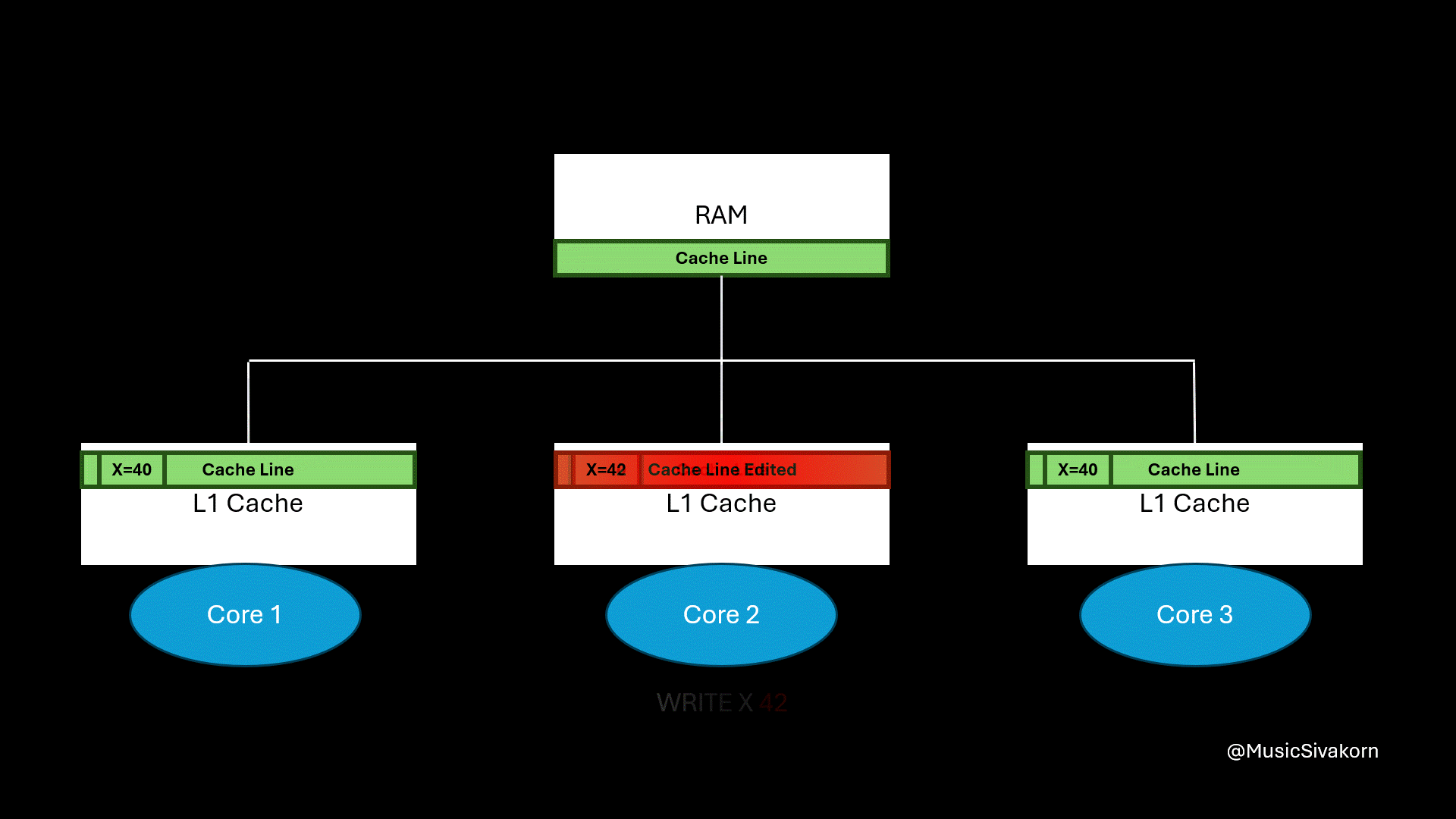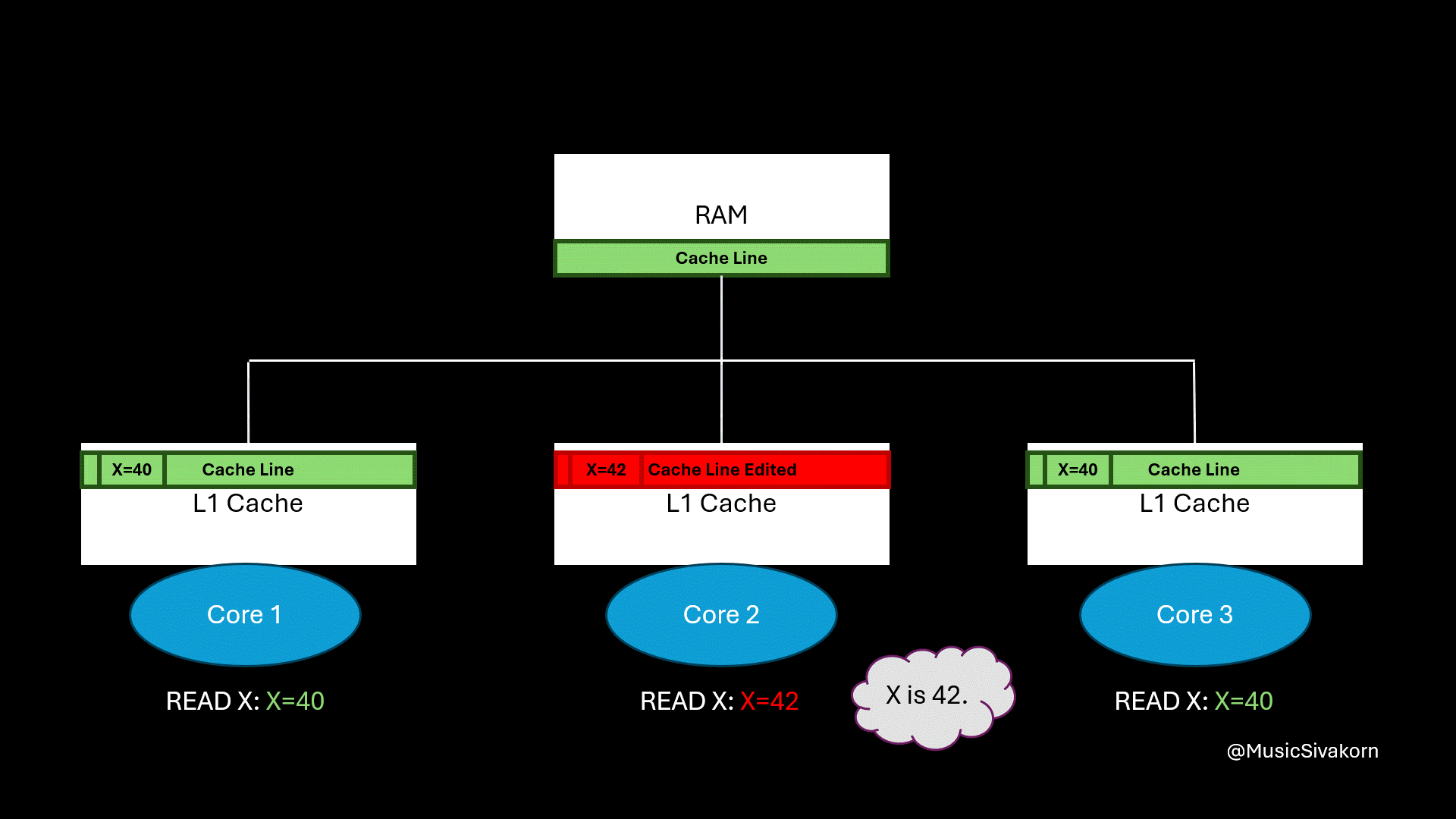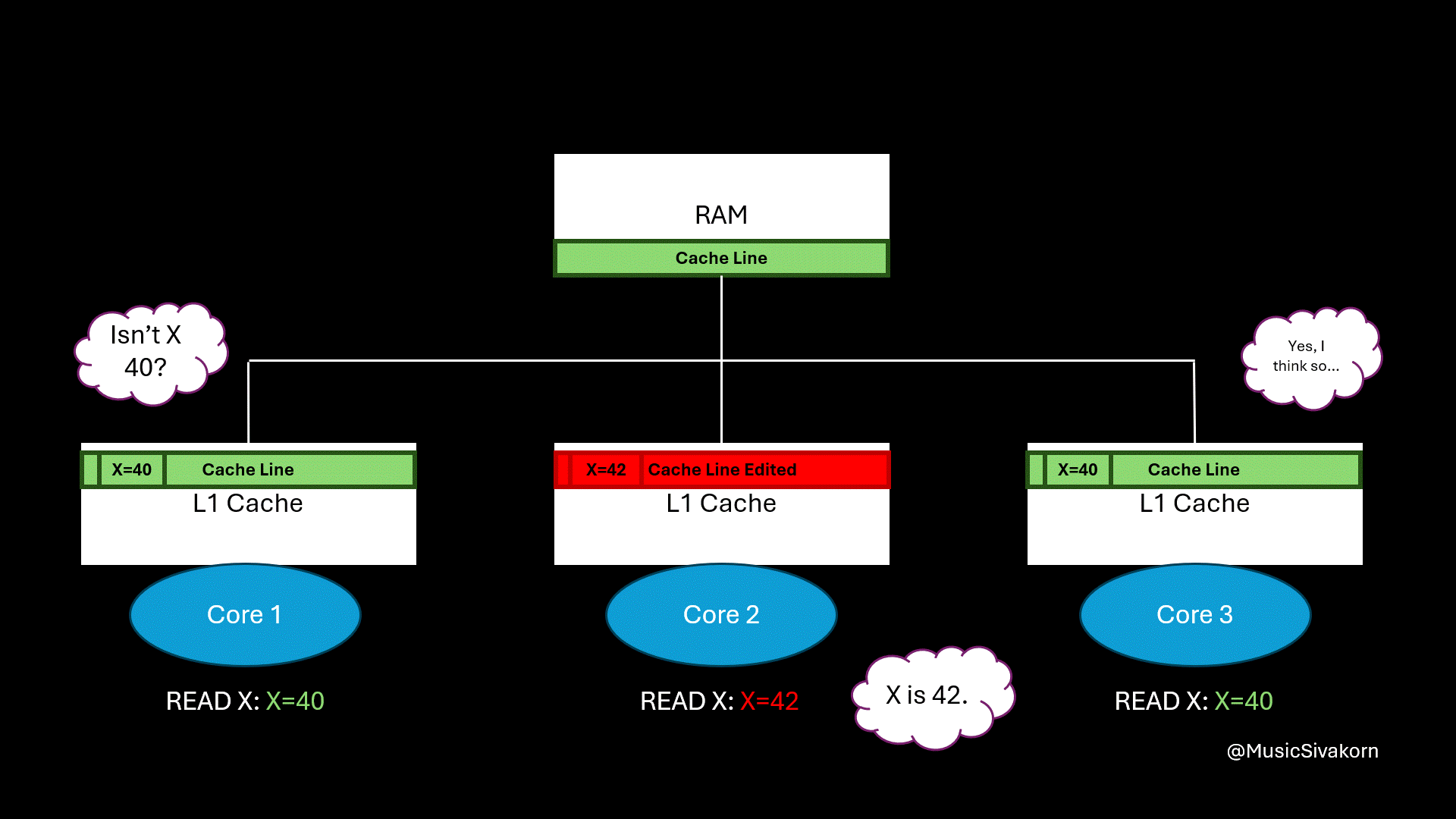
The second core updates a variable on a cache line that is also available in other cores.
From this example, the second core updates the variable x on its cache line. Only the second core sees the updated value. The remaining cores, which are the first and third core, still see the old value of x because they read from their own, now stale, cache line. In other words, different cores can hold different value for the same variable. This situation brings about inconsistency, which is dangerous when programs (threads, to be more precise) on different cores rely on shared memory (using the same RAM in this case) for coordination.
This series will dive into cache coherency, a mechanism that prevents this inconsistency and ensures all CPU cores to see the most updated and consistent value of a given memory location, making parallel computing reliable.
The first and third core must update their cache line to be consistent with the second core.
How this Mechanism Works.
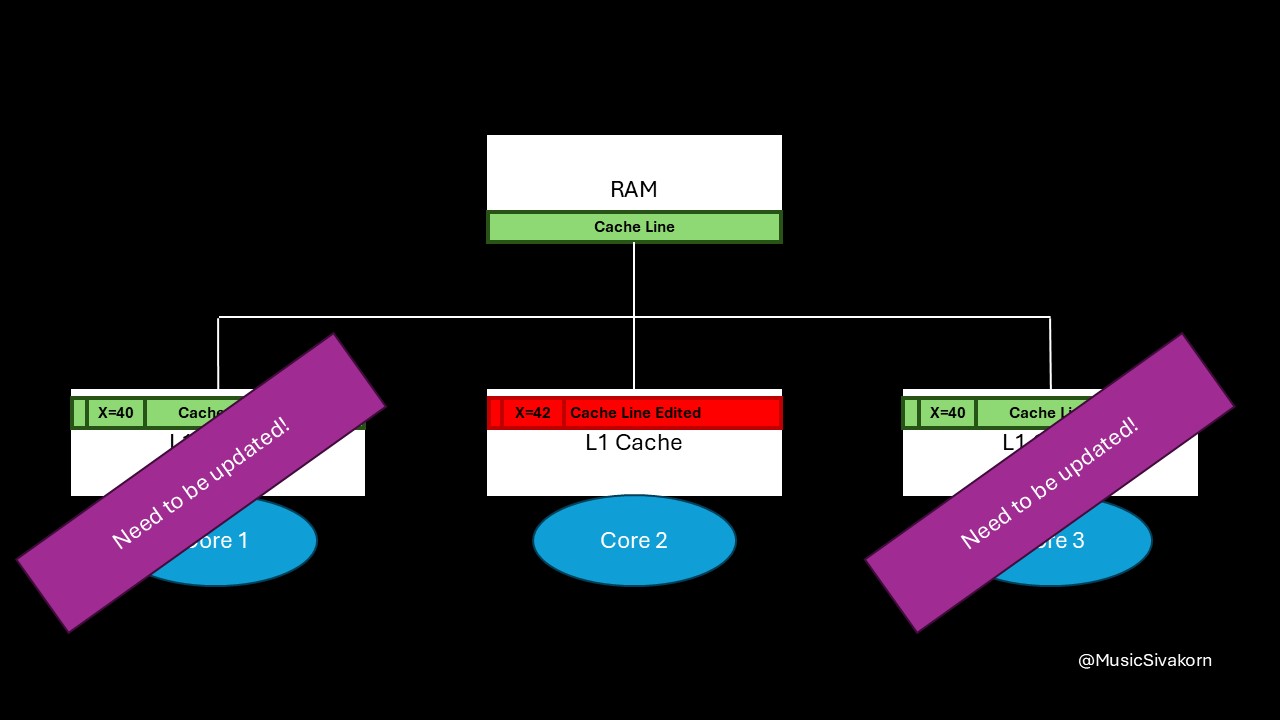
When a core modifies data in its cache, it must notify other cores by sending an invalidation signal through the system bus. This signal tells other cores that their cache line is now stale and must not be used.
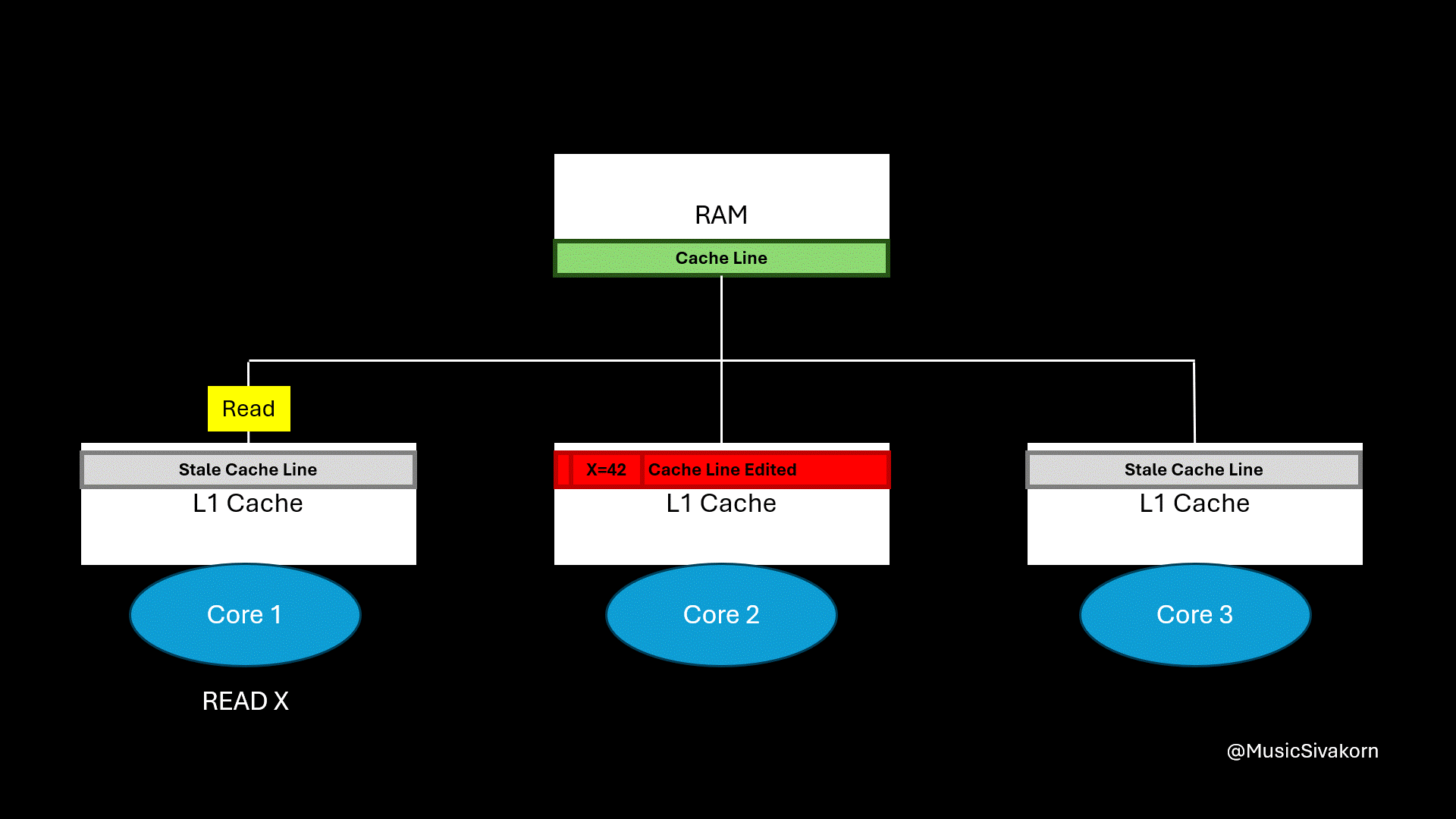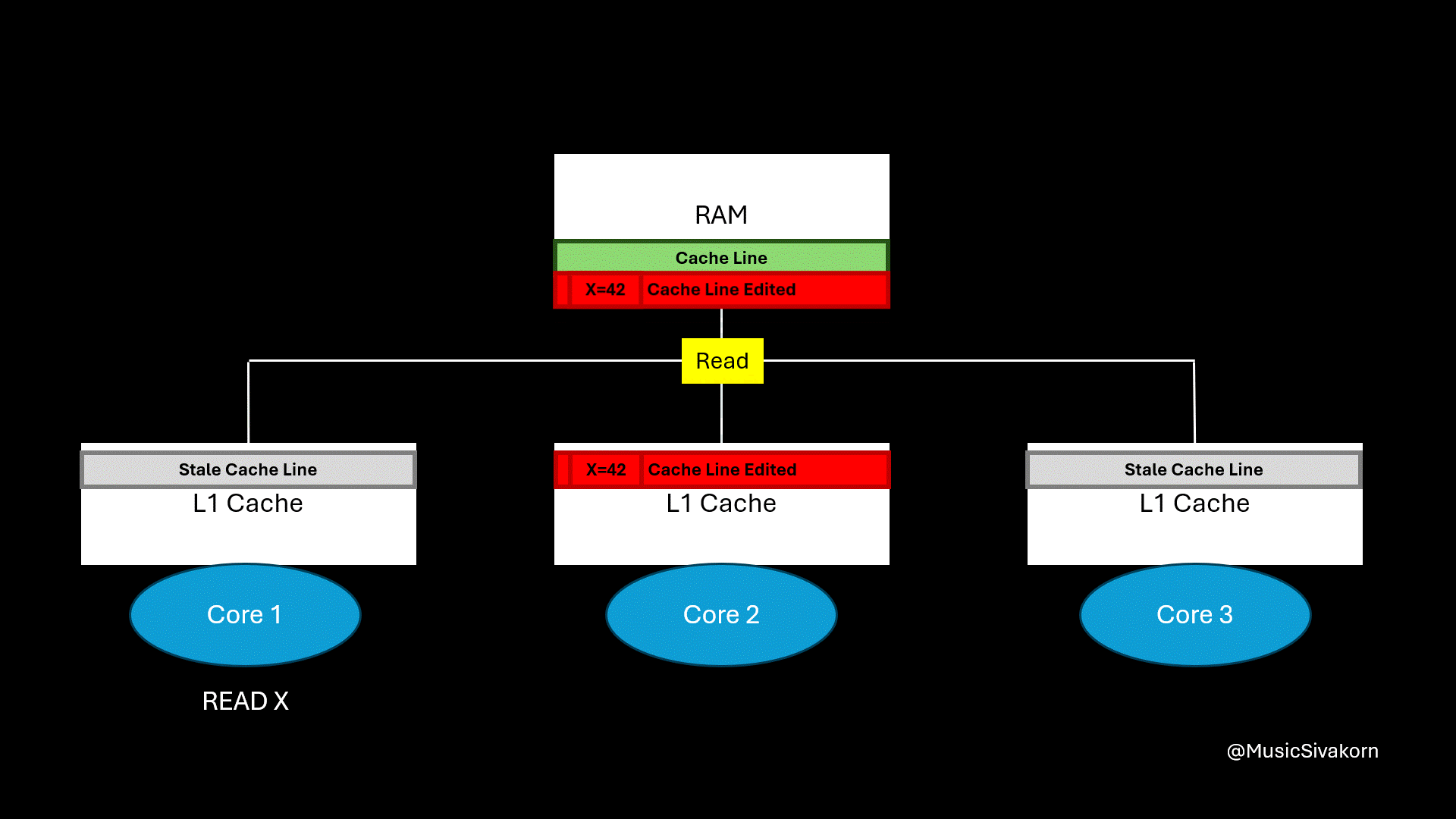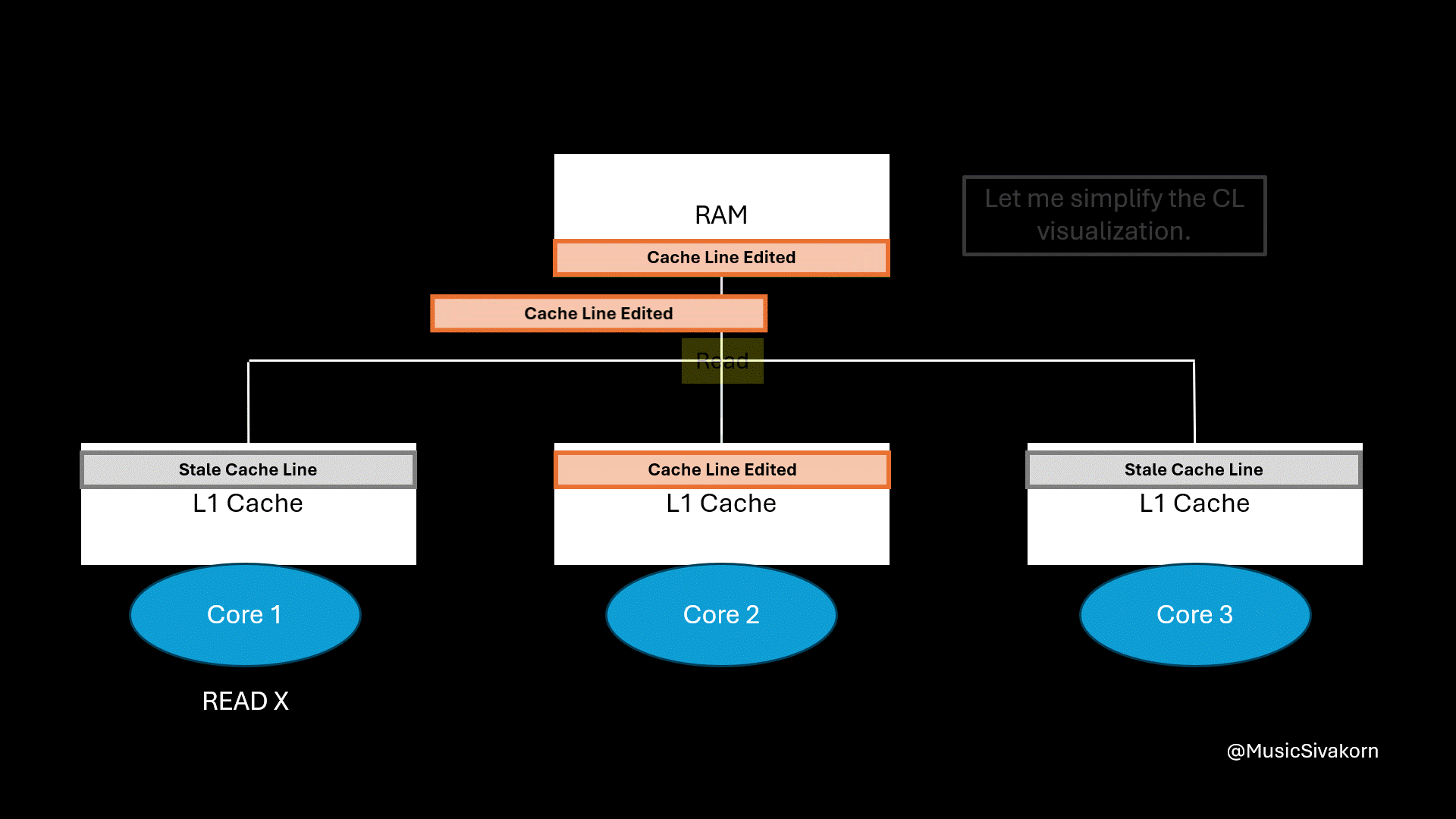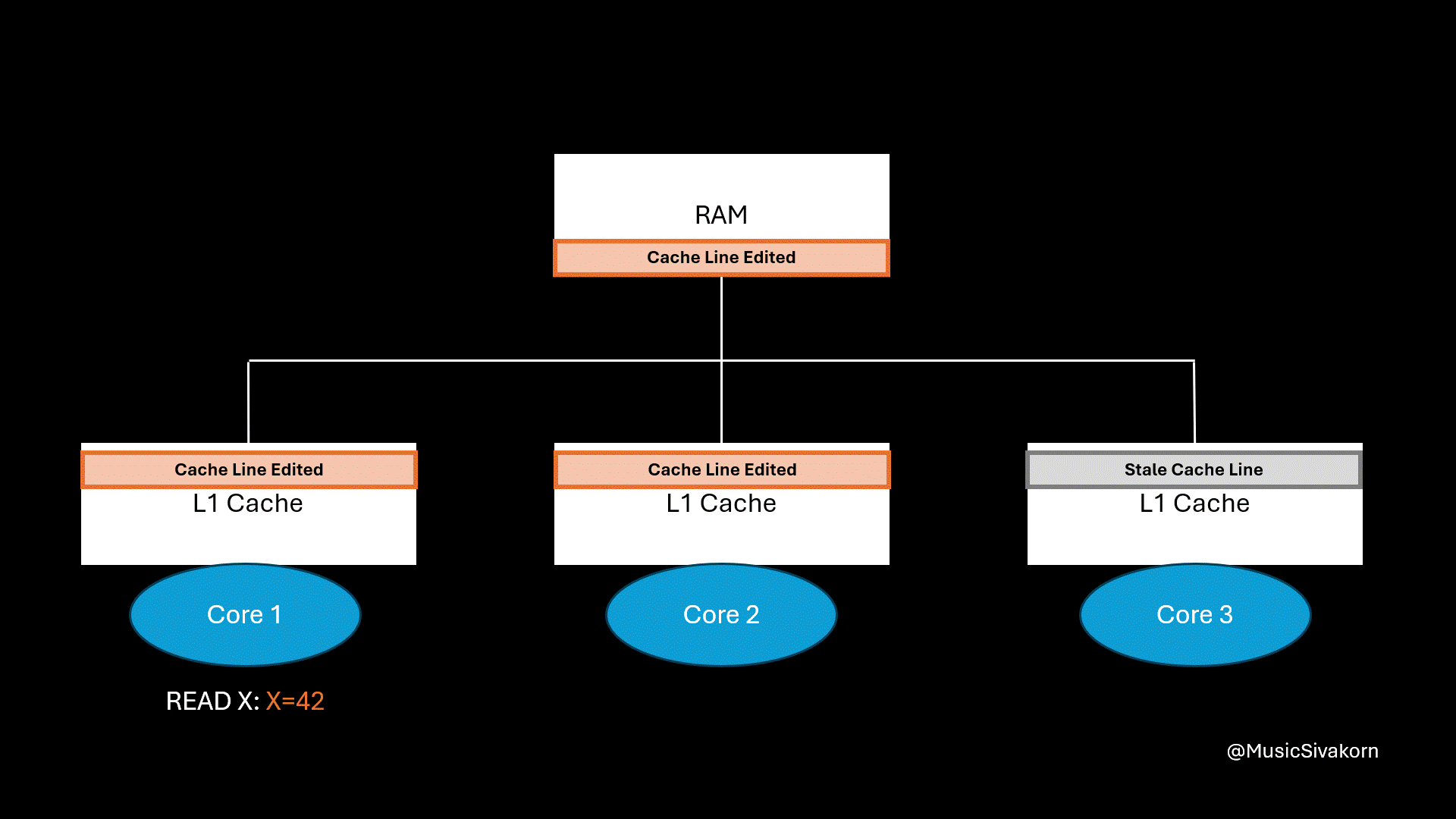
In the following visualization, the second core broadcasts the invalidation message through the bus. The cache line in other cores is marked invalid and become a stale cache line. If the core tries to access its stale cache line, a cache miss occurs. As a result, if the core wants to read updated data, it has to send a read request signal to the bus to fetch a new updated cache line from RAM.
Can you spot any problem here?
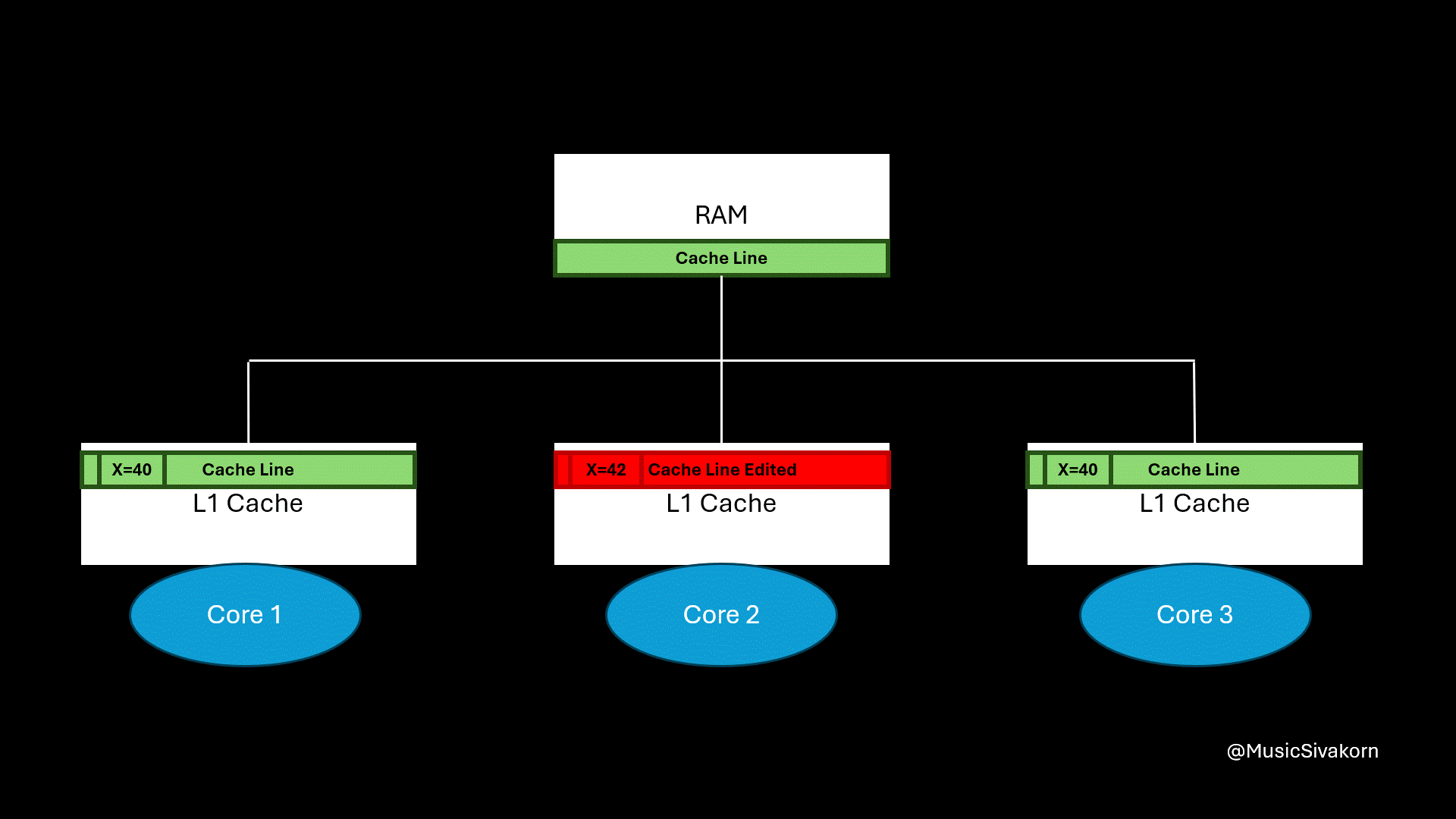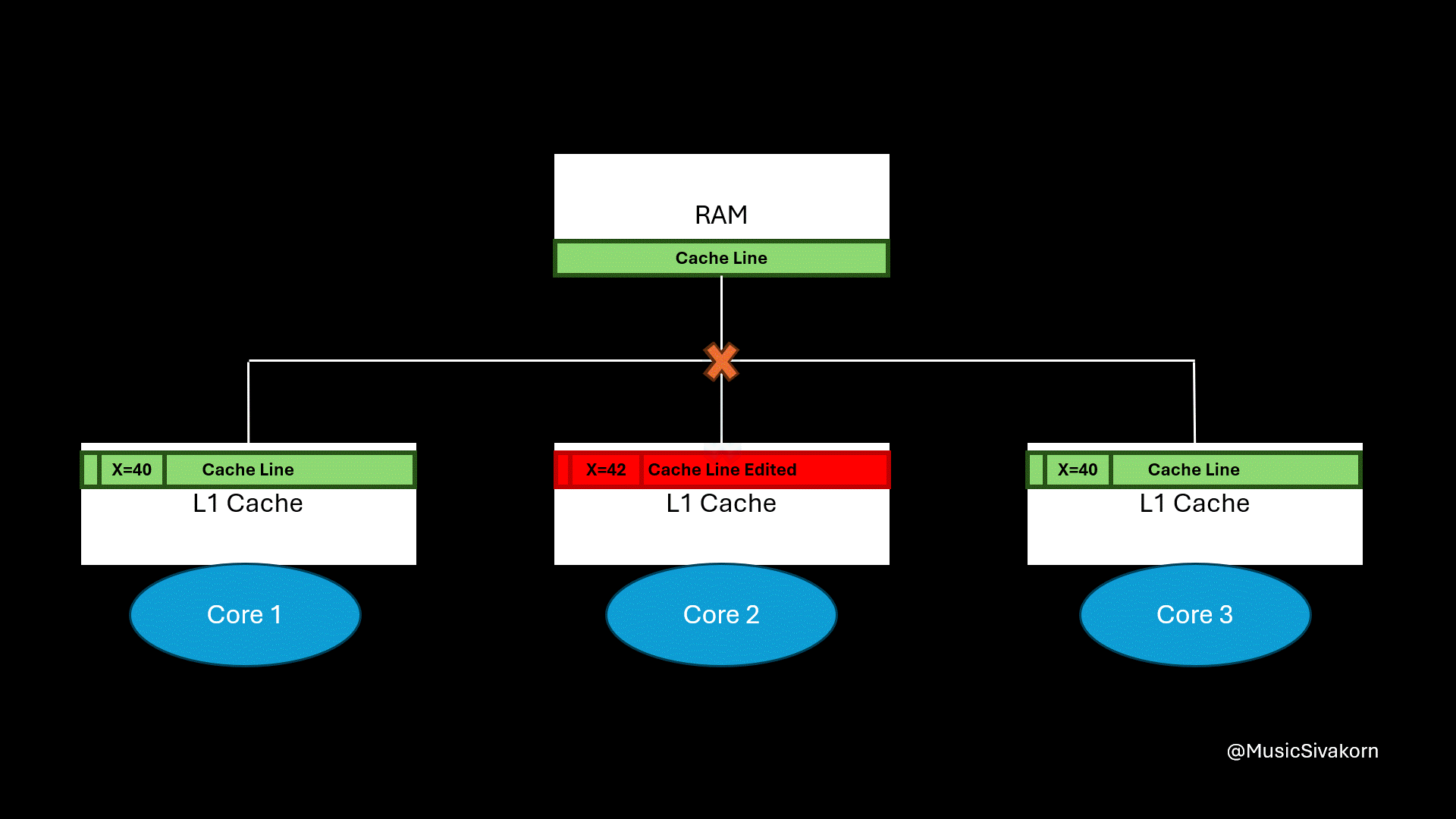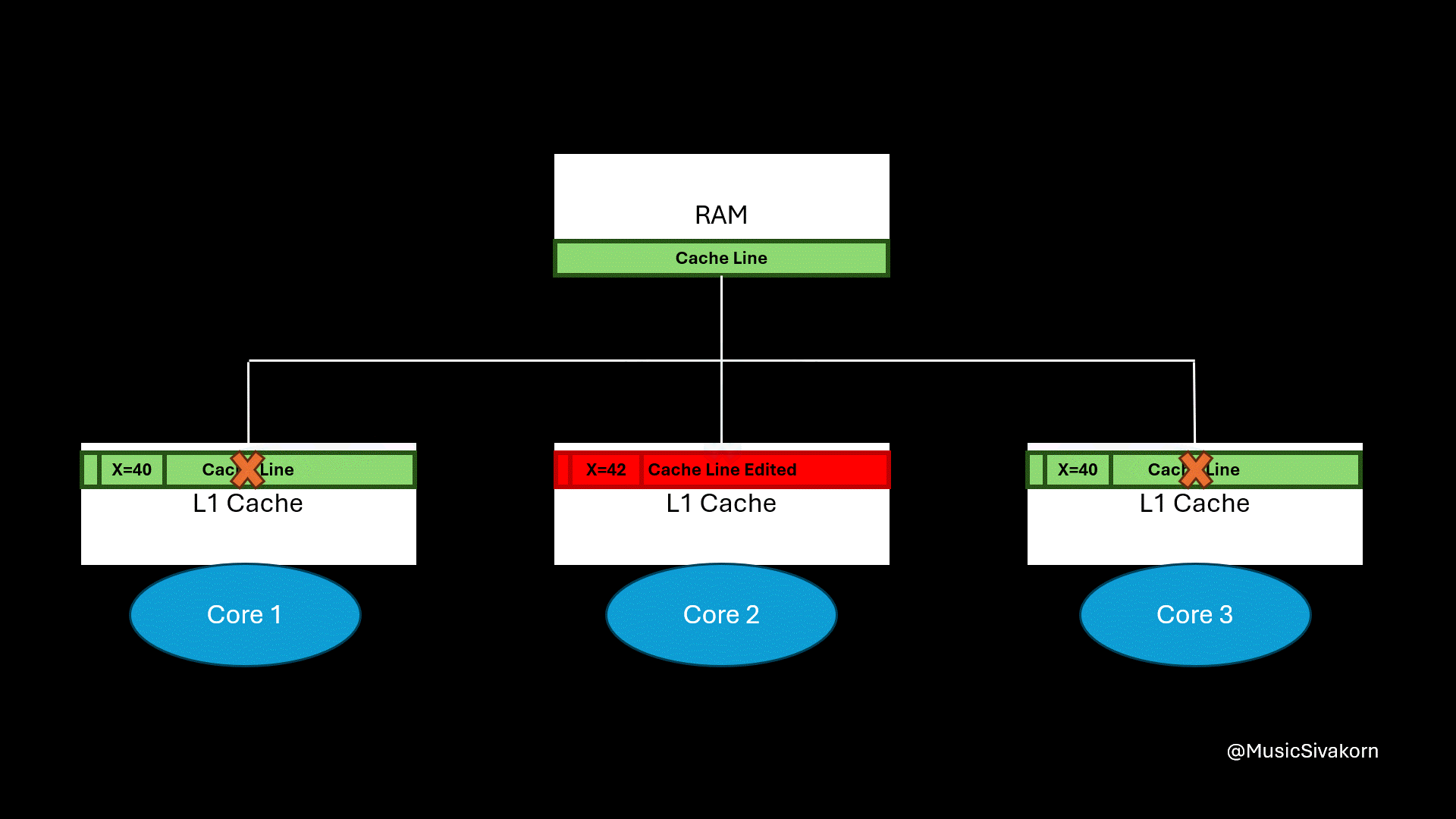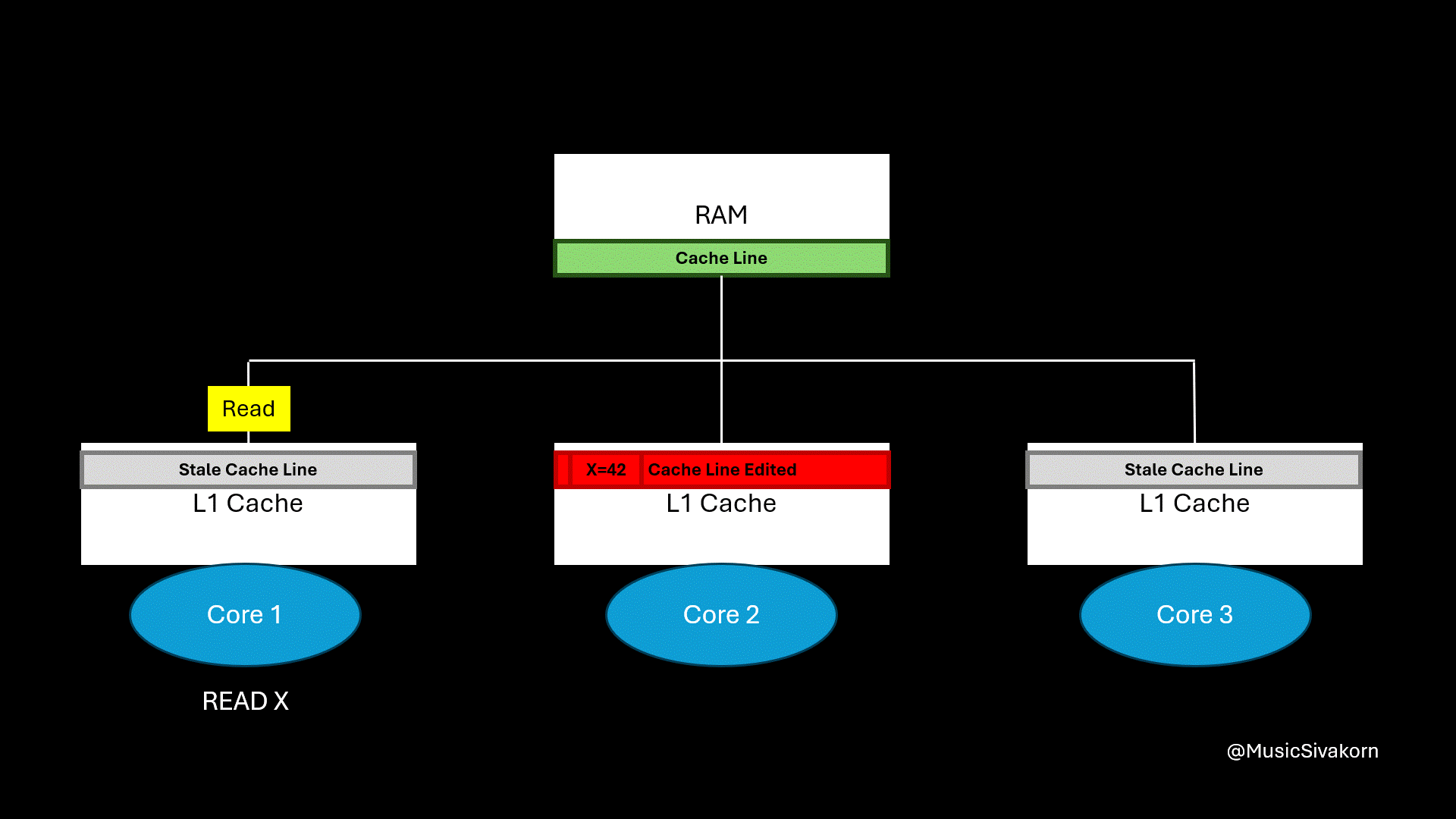
The second core sends an invalidation signal to the other cores to invalidate their cache line. Then, the first core sends the read request when it wants to read the value of X
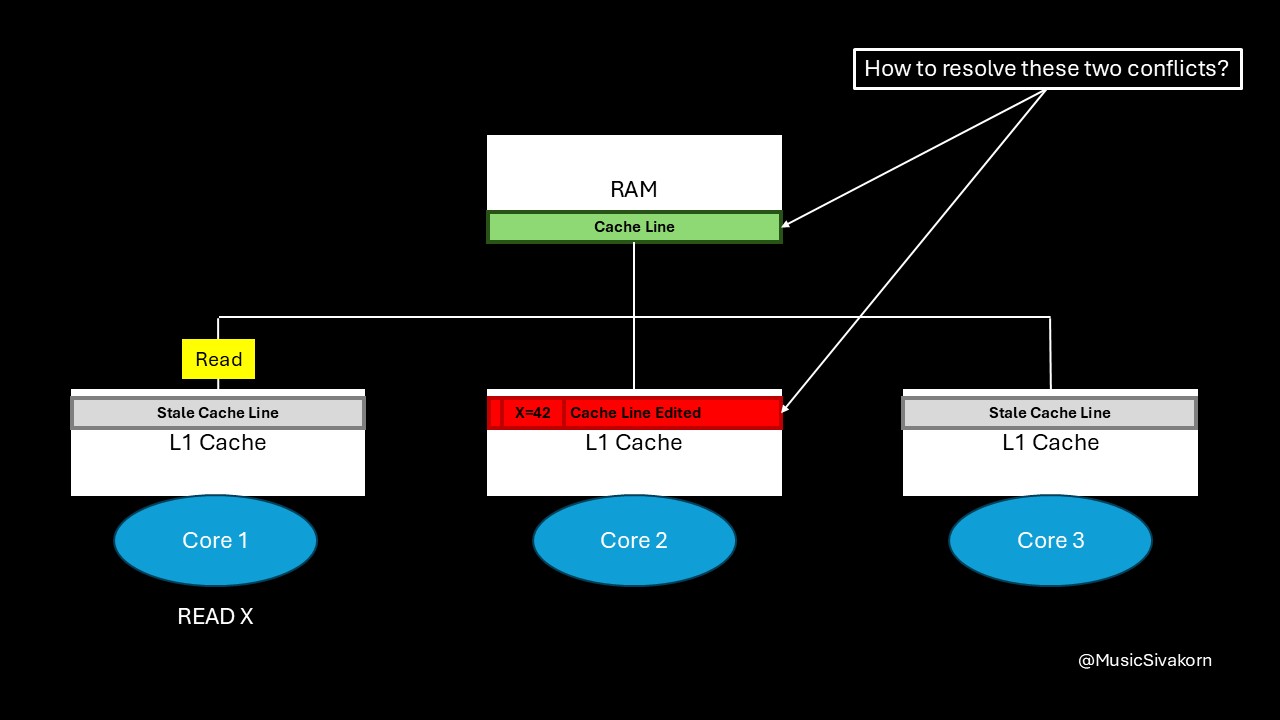
The problem is that there is now a discrepancy between the RAM cache line and the updated cache line in Core 2. If another core accesses the data directly from RAM at this point, it would still get the old, outdated value, leading to further inconsistency. How should we solve it?
A solution is for the core that made the update to write back the modified cache line to RAM. Then, another core trying to read the same memory address can retrieve the latest cache line from RAM.
After the first core sends a read request, the second core writes an updated cache line back to RAM. Then, the first core retrieves it.
The problem is solved! The first and second core now reads the same value of the variable x because they now have the same cache line.
It looks good now, doesn’t it?
No, it doesn’t. Of course, this mechanism provides a consistent view of data to all cores, but can you spot any inefficiency in this mechanism? Is there any unnecessary overhead in the current solution? Think about it!
My face when I learned the cache coherence mechanism for the first time in Parallel Programming class.
The short answer is “accessing RAM is slow”. But how can we decrease this latency? In the next part (part 2), I will rewrite this mechanism in a more formal way and discuss how to optimize it.
If you enjoy this blog, you can support me with a cup of coffee. Thank you for reading until here and see you then!
SIDE NOTE: When referring to RAM and main memory, they are mostly DRAM, while the cache is made from SRAM. SRAM is faster than DRAM.
This blog is originally published in Medium.